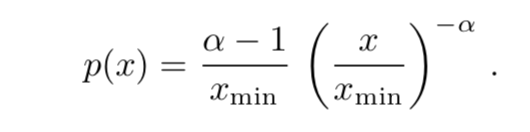Introduction¶

There can be no doubt about it -- soccer is growing incredibly rapidly in the United States. MLS player salaries go up every year, as does average attendance for MLS games. And the league is still actively expanding. The number of high school soccer players has grown by 30% since 2004. And we have a world cup winning woman's team!
MLS salaries are pretty high by normal people standard, with a median income of $179,000 but relatively low by professional player standards. Keep in mind that the average NFL player makes a median salary of $860,000.
In this tutorial, our goal is to analyze the distribution of soccer players' salaries, find what factors determine a soccer player's salary, and see if we can predict a soccer player's salary from their stats. We should be able to use the exploratory data analysis techniques and machine learning algorithms we learned in class to do so.
It is my hope that this tutorial will provide some insights into what skills a soccer player should have to be considered "valuable" by professional teams. It is well-documented that many MLS players are unhappy with their salary -- over a third make less than $100,000 a year. While I can't provide any macroeconomic solutions to these problems, hopefully I can give people some insight into how they should train if they want a pay raise.